寒いですね。なんかすんごく太りました (x_x)
SQLの本で「なるほど」ってなったことを書きます。
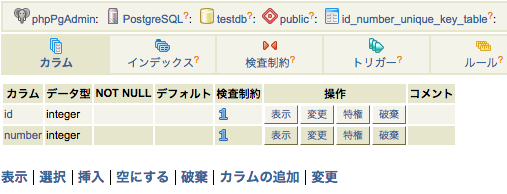
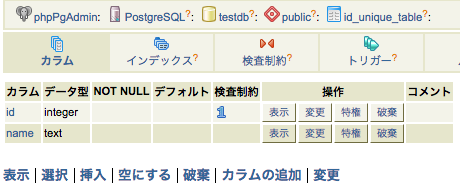
■SERIAL型 …連番をふることができる。(postgreSQL)
CREATE TABLE test_db(
id smaillint,
name text
);
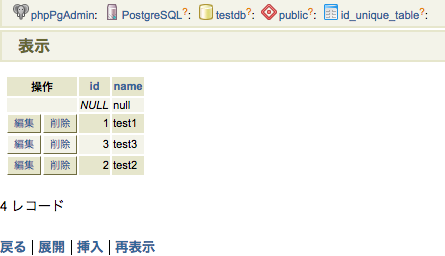
INSERT INTOtest_db VALUES(1,'ガズ');
INSERT INTO test_db VALUES(2,'シャーロット');
INSERT INTO test_db VALUES(3,'マーニー');
今時点では
id | name |
——–+————–+-
1 | ガズ |
2 | シャーロット |
3 | マーニー |
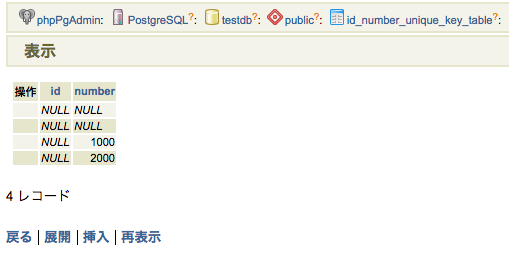
そこに、SERIAL型のカラムnumberを追加する。
ALTER TABLE test_db ADD COLUMN number serial;
id | name | number
——–+————–+——–+—–
1 | ガズ | 1 |
2 | シャーロット| 2 |
3 | マーニー | 3|
勝手に連番ふってくれる!!!
CREATE SEQUENCEをしなくても、シーケンスをつくってくれます。
カラムnumberを指定しなくても連番を勝手にいれてくれる!
INSERT INTO test_db VALUES(4,'アーロン');
id | name | number
——–+————–+——–+—–
1 | ガズ | 1 |
2 | シャーロット| 2 |
3 | マーニー | 3|
4 | アーロン | 4|
�■複数の論理演算子の優先度
(1) NOT
(2) AND
(3) OR
■ JOIN の色々
▶︎INNER JOIN(内部結合)
書き方: JOIN テーブル名
片方にしか存在しない行は結合されない
▶︎OUTER JOIN(外部結合)
・FULL OUTER JOIN
書き方: FULL (OUTER) JOIN テーブル名
片方にしか存在しない行でも他方をNULLにして結合する
・LEFT OUTER JOIN
書き方:LEFT (OUTER) JOIN テーブル名
左テーブルにしか存在しない行は右テーブルをNULLにして結合する。
右テーブルにしか存在しない行は結合されない。
・RIGHT OUTER JOIN
書き方:RIGHT (OUTER) JOIN テーブル名
右テーブルにしか存在しない行は左テーブルをNULLにして結合する。
左テーブルにしか存在しない行は結合されない。
■集合関数におけるNULLの扱い
SUM/MAX/MIN/AVG … NULLは無視
→NULLを0に置き換えて集計したい時は、COALESCE関数を使うといい。
COUNT … カラム名指定の場合、NULLはカウントしない。
しかし、「*」の時はNULLを含めてカウントする。
→count(カラム名)とcount(*)で結果が異なることがある。
■SQLの区分
・DML …Data Manipulation Language – データ操作言語
SELECT / INSERT / UPDATE / DELETE など
・DDL …Data Definition language – データ定義言語
データベース、テーブル、ビューなどの基本データを定義・作成するための言語。
CREATE / ALTER / DROP など
インデックスやシーケンスを含む。データベールオブジェクトと言うこともある。
・DCL …Data Control Language – データ制御言語
データベースのユーザー権限の管理やデータのトランザクション処理を行う為の言語
GRANT / REVOKE / BEGIN / COMMIT / ROLLBACK など
■トランザクション
…複数の指示をひとかたまりのSQL文として扱うこと。
「一方のテーブルでは差し引き、他方のテーブルでは差し引いた分足す」
といった指示間を他の人に邪魔されると一貫性がなくなるものとかに使う。
トランザクション制御を扱うためのSQL
・BEGIN: 開始の指示。この指示以降のSQL文を1つのトランザクションとする。
・COMMIT: 終了の指示。この指示までを人のSQL文とし、変更するを確定する。
・ROLLBACK: 終了の指示。この指示までを人のSQL文とし、変更するを取り消す。
→ACID特性 の 原子性(1か0か)
■似た言葉だけど全然違う、ロールバックとロールフォワード。
・ロールバック…実行した処理を取り消す。SQLの実行失敗やデッドロークなどで発生する。
・ロールフォワード …まだ実行されていない処理を実行する。
障害復旧時、バックアップにより障害前の状態にした後、ログより、障害前から障害直前の状態までデータを更新すること。
■設計について
▶︎一般的な設計手順
(1)概念設計
(2)論理設計
(3)物理設計
▶︎正規化 ….(2)論理設計の時にする。
・第一正規形:繰り返しの列、重複列がない。
・第二正規形:部分従属がない
(例)部分従属とは…{A,B}→C = A→CまたはB→C
・第三正規形:推移従属がない
※推移従属とは…{A,B}→C = A→BかつB→CでB→Aではない。
(例)クラス→出席番号→名前
名前は、クラスと出席番号が特定されないとわからない、そんな関係性。
実際読んだ本がこちらです↓